Concepts¶
This section explains the concepts and architecture of LiuAlgoTrader framework.
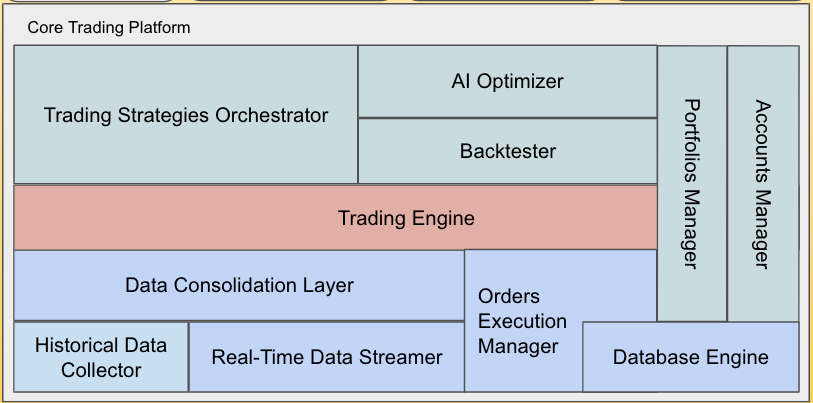
Building Blocks¶
The framework executes two components in parallel: Scanners and Strategies.
- Scanners, or stock screeners as called by some platforms, is run periodically to search for stocks from the stock universe that adhere to criteria of choice. Users can easily create and deploy scanners, with only few lines of Python code. Scanners determines the time to subscribe for events of a specific stock. Events could be price changes, quotes or trades in a predefined window, e.g. per second/ per minute.
- Strategies receive stock events from stocks selected by the scanners and then analyse the stock movement by a wide range of indicators to decide the action on the selected equities. A Strategy may act on movement of a single stock or a collection of stocks. A Strategy could also reject a stock and unsubscribe for its further events. The framework supports both long and short positions to equities. The framework is designed to be capable of concurrently handling hundreds of stocks as a portfolio with numerous strategies. Scanner could decide to address stock events with a specific strategy or all strategies.
Data Propagation¶
Data is either loaded directly from a data-providers, or updated in real-time using web-sockets.
- DataLoader() class introduces a DataFrame-like interface to load data from a data providers, or updating data from web-sockets,
- StreamingAPI() and DataAPI() are abstract classes for integrating data-providers (there are implemented connectors for both Alpaca and Polygon),
- data_loader_factory() instantiates implementation for StreamingAPI() and DataAPI(), based on the selected data-providers,
- Trader() is a base-class for integration Broker APIs (only Alpaca is currently supported),
DataLoader class¶
The DataLoader class is fundamental in creating a strategy using LiuAlgoTrader. It allows access to data without the need to pay attention to any connectivity details and is consistent among the different data providers. The Framework is responsibility for constantly maintaing an updated DataLoader class, which is passed a long to the strategy during its execution.
Usage Fundamentals¶
The framework consists of 3 base classes: Scanner, Strategy and Miner. Scanner and Strategy are for basic trading activities, while Miner are for advanced off-market calculations. The framework comes with a generic Scanner, though we recommend to treat it as a reference.
To get start with the framework, you should create your custom scanners and strategies, inheriting from base classes Scanner and Strategy. Once the building blocks are in place, you can instruct the framework which scanners & strategies to instantiate in tradeplan.toml file, together with configuration parameters that you would like to pass for each.
All your trading activities are stored in a database, and all trades are automatically analyzed at the end of a trading session. You can then use a multitude of notebooks for further analysis and improving the performance of your algo trading strategies.
Hands-free framework¶
LiuAlgoTrader is designed to be a (nearly) high throughput & scalable framework, that optimizes at utilizing the underlying hardware.
It is designed to be a hands-free framework for strategy developers without the need to worry about low-level considerations such as connection issues.
High Level Architecture¶
Polygon.io, Alpaca and other real-time stock data providers provide data via WebSockets. In most cases data providers become impatient when posted data is not timely collected by the intended recipient.
LiuAlgoTrader implements a producer-consumers design pattern, where a single (or multiple) producer process interacts with the data provider, and multiple consumer processes are handling the algorithmic decision making and initiate trades via API calls.
Below diagram visualizes the high-level call flow & system components
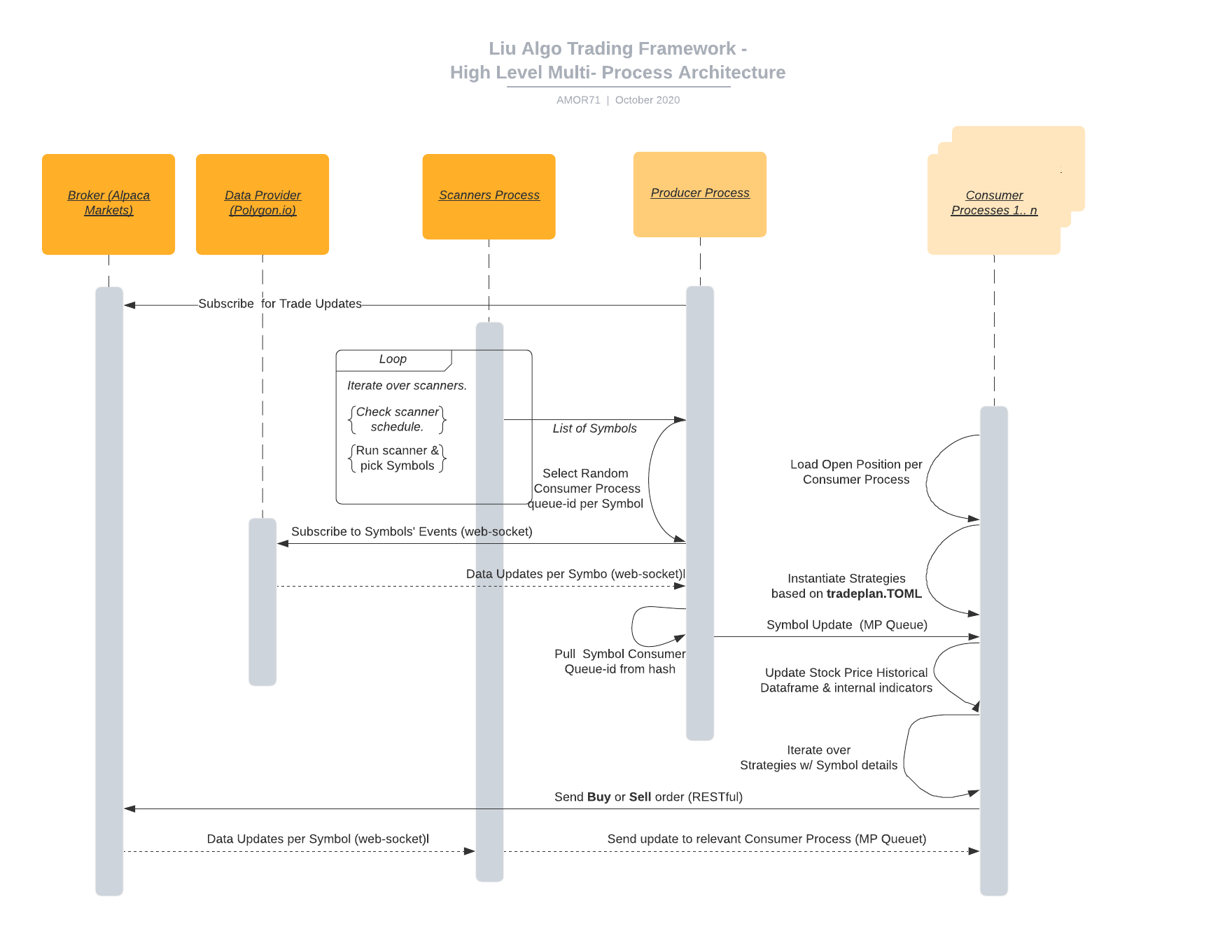
Implementation details¶
LiuAlgoTrader is implemented using multi-process infrastructure, and each process uses asyncio for inter-process lightweight threading (The framework works w/ 3.8 and above). This architecture provides high throughput which maximizes the hardware capabilities.
A link between a producer and a consumer is maintained by a Python multi-processing Queue. Each consumer has a designated cross-process Queue and a pre-defined list of stocks that the process is tracking. The producer’s role is to receive updates from the WebSocket, post them into the relevant consumer’s Queue, and return to process the next message.
Each consumer reads events from the Queue, parses them the calls the strategies selected in the tradeplan configuration file.
Upon running the trader application, scanners would run and stock would be picked. Based on the number of stock, and the available CPUs consumer processes would be spawn. As they start, the producer process is spawned, and the communication with the data-stream provider is initiated.
Performance¶
Each consumer would check the time-stamp of the received events. If the events are more than 5 seconds behind, the message will be discarded, and the consumer queue would be cleaned. This allows a quick catch-up at the expense of losing data. When such catch-up takes place the following message would be written to the log:
consumer A {symbol} out of sync w {time_diff}
When you see such a message repetitively, it may mean that either:
- The Strategy being used takes too long to calculate compared to the number of stocks handled by that single process. It will be a good idea to double-check the Strategy code, and check if performance improvements are possible,
- It is possible that the Strategy writes too much log that causes delays,
- The number of stocks traded is too high for the hardware setup. In that case it would be best to reduce the max number of stocks (environment variable)
- The consumer process listen to second message, as well as trade and quote messages, depending on the strategy and hardware capacity it might be best to reduce the event types that the producer is sending to the consumers (change the tradeplan configuration file),
Understanding the project structure¶
NOTE the project structure may change periodically, please check our GitHub repo for the most accurate structure.
Understanding the project structure is the first step in uncovering the tools available to the custom strategy developer. Below is the project structure highlighting important files for a future developer.
├── AUTHORS
├── LICENCE
├── CONTRIBUTING.md
├── CODE_OF_CONDUCT.md
├── analysis
│ ├── backtester_ui.py
│ ├── day_trade_ui.py
| └── notebooks
│ ├── portfolio_performance_analysis.ipynb
│ └── backtest_performance_analysis.ipynb
| └── ...
├── design
| └── various design & concepts documents
├── liualgotrader
│ ├── common
| | ├── types.py
| | ├── config.py
| | ├── market_data.py
| | ├── tlog.py
| | ├── data_loader.py
| | └── trading_data.py
| ├── data
| | ├── data_base.py
| | ├── streaming_base.py
| | ├── data_factory.py
| | ├── polygon.py
| | └── alpaca.py
| ├── trading
| | ├── base.py
| | └── alpaca.py
│ ├─── analytics
| | ├── analysis.py
| | └── consolidate.py
│ ├── fincalcs
| | ├── candle_patterns.py
| | ├── support_resistance.py
| | └── vwap.py
│ ├── models
| | ├── algo_run.py
| | └── ...
│ ├── miners
| | ├── base.py
| | ├── stock_cluster.py
| | ├── gainloss.py
| | └── daily_ohlc.py
│ ├── scanners
| | ├── base.py
| | └── momentum.py
│ ├── strategies
| | ├── base.py
| | └── momentum_long.py
│ ├── consumer.py
│ ├── scanners_runner.py
│ └── polygon_producer.py
|
├── examples
├── tools
└── tests
common¶
The common folder contains 5 important files that the developer should be aware of:
- config.py is a file for global configuration. The file includes internal constants which are not accessible via the environment variables of the configuration file for now,
- types.py includes various enums/classes used throughout the framework,
- tlog.py is a simple log implementation which write log entries both to STDOUT and GCP stackdriver logger, if it is configured,
- data_loader.py explained above,
- trading_data includes global variables that are shared between the strategies and the consumer infrastructure. This file should be viewed in details to understand data passing.
fincalcs¶
The folder includes packages for basic financial calculations. Those are helper functions for strategy developers:
- candle_patterns.py - implements basic candle patterns
- support_resistance.py - implements basic algorithms for calculations of horizontal support and resistance lines.
- vwap.py - accurate calculation of 5-min VWAP, helpful for VWAP based strategies.
models¶
Data abstraction layer implementing the persistence and loading of the data model.
Data Model¶
The following diagram represents the conceptual models which constitute the framework. It is important to understand different concepts, and their relations, when developing strategies using the platform.
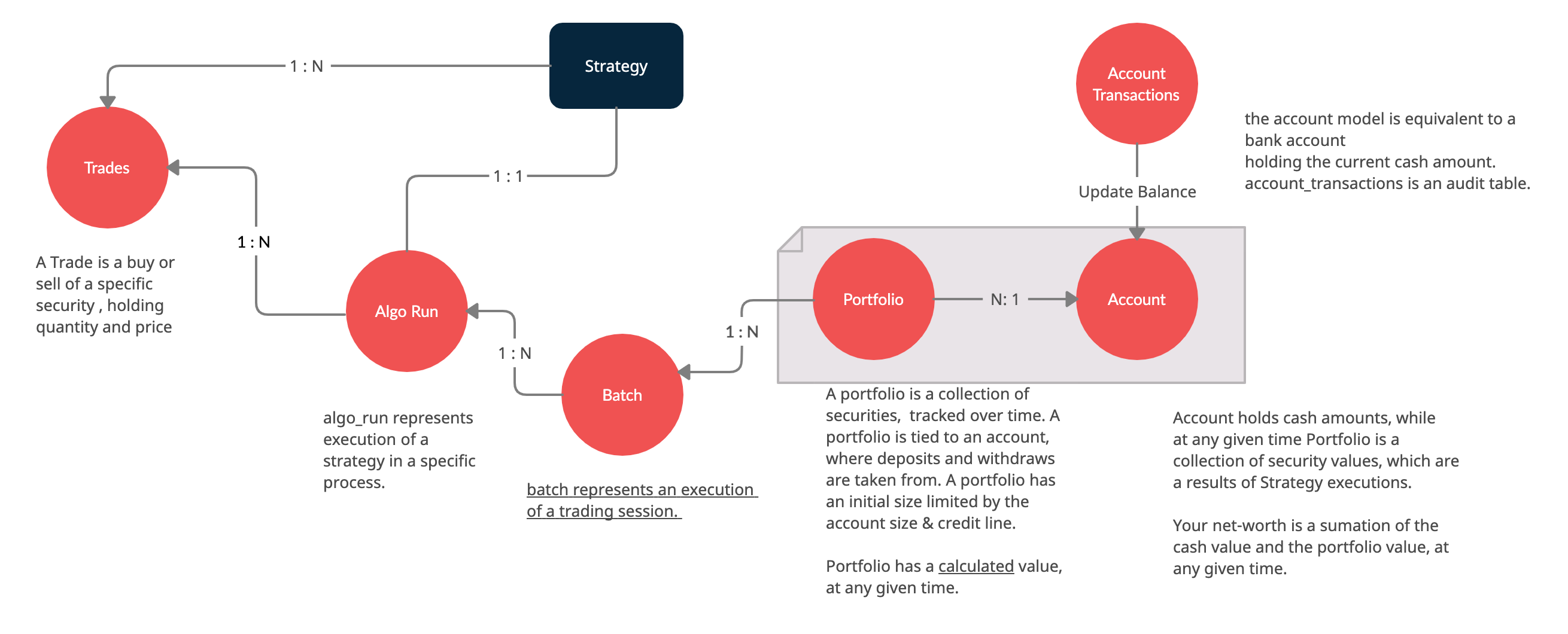
- To browse the entire database schema: https://amor71.github.io/LiuAlgoTrader/dbspy/
- To view the relationships between the tables: https://amor71.github.io/LiuAlgoTrader/dbspy/relationships.html
The data-model, as represented in the database tables can be used by various strategies, as well as for analysis and back-testing.
This section describes the database schema and usage patterns.
batch_id¶
Each execution of the trader application generates a unique-id internally referred as a batch_id.
main database tables¶
The main database tables are as follows:
| Name | Description |
| stock_ohlc | Daily OHLC “cache” for back-testing. |
| trending_tickers | Tracks of selected stocks per batch_id, including time-stamp. |
| algo_run | Strategy execution log, per batch_id and consumer process. More details below. |
| new_trades | Tracks of each executed order (including partial), per algo_run, including whatever reasoning is persisted by the executed strategy. |
| gain_loss | Tracks of per symbol and per algo_run profit & loss, measured as percentage and absolute value. |
| trade_analysis | Tracks of per trade, the r_units, profit & loss, measured as percentage and as absolute value. |
| portfolio | Tracks of securities value over time. |
| portfolio_batch_ids | Table associating portfolio to batches. |
| keystore | Key/Value repository. Convenient for Strategies to track values cross batch executions. |
| accounts | Bank-account equivalent. Mostly used to keep track of portfolio cash amounts. |
stock_ohlc table¶
- symbol
- symbol_date
- open
- high
- low
- close
- volume
- indicators JSONB,
The table holds daily OHLC values, per stock, including indicators that we collected and calculated using the data_miner application.
algo_run table¶
The table entry is created by the consumer process, upon and execution of a strategy. Therefore, each line in the table represents an executed strategy, per process, per batch_id.
The table tracks a collection of information that helps to reconstruct the trading day and analysis it post-analysis and back-testing:
- batch_id
- start and end time-stamps. If an end-date is missing, it means execution was stopped during the trading day.
- strategy name
- environment (PAPER, BACKTEST, PROD)
new_trades table¶
the table persists each trading operation (including partial fills), each trade is linked to an algo_run_id (a unique-id per algo_run row).
The table tracks:
- symbol
- amount & price
- algo_run_id
- database time-stamp and client time-stamp: the executed time-stamp of order.
- target/stop price (if available)
- indicators - a JSON construct that may be filled by the strategy in any way fitting post analysis.
Additional tables¶
ticker_data¶
The ticker_data table keeps basic data on traded stocks which include the symbol name, company name & description as well as industry & sector and similar symbols.
It is recommended to use the market_miner application to periodically mine fresh data.
The industry & sector data is informative for creating a per sector / industry trend.
gain_loss¶
The table holds the percentage and value gained per stock, per strategy for a batch_id. The table is populate at the end of a trading session, or using market_miner.
trade_analysis¶
The table holds gain & loss, per trade in percentage, value, as well as r units. The table is populated at the end of a trading session, or using market_miner. The table is used for performance analysis of a trading session.
portfolio¶
Holds a calculated portfolio, that may be calculated during off-market hours and used by a strategy as a reference.